

Anthropic Just Went to 1M Tokens. So Did Everyone Else. That's the Point.
Google matched the price. Now Anthropic matched the context. Is this DeepSeek V4 forcing the race? A 360° convergence angle.


Anthropic just made 1 million token context generally available on both Claude Opus 4.6 and Sonnet 4.6. That means you can now load entire codebases, hundreds of legal contracts, or massive document sets into a single conversation. A year ago, this was bleeding-edge. Today, it’s a checkbox.
And that’s exactly the point.
Because Anthropic isn’t first here. They’re only catching up.
The Chase
Here’s what happened in roughly 12 months:
DeepSeek ships V3 with sparse MoE, open weights, and token pricing so cheap it makes Western labs look like luxury brands
Google responds by launching Gemini Flash at $0.30 per million tokens » directly matching DeepSeek’s price band — with 1M context already baked in
OpenAI prices GPT-5 at $1.25 per million input tokens » down from GPT-4’s original $30. TechCrunch calls it the start of a “price war”
Anthropic, the last holdout on long context, ships 1M on both Opus and Sonnet in the same month
DeepSeek V4 » a trillion-parameter, native multimodal model with 1M context and O(1) memory » still hasn’t officially shipped. And it’s already forced all of the above
Every move in this sequence is a response to the move before it.
DeepSeek set the price. Google matched it. OpenAI undercut their own previous pricing by 24x. And Anthropic just said “fine, we’ll match the context window too.”
That’s not independent innovation. That’s a chase.

But Context Length Alone Isn’t the Story
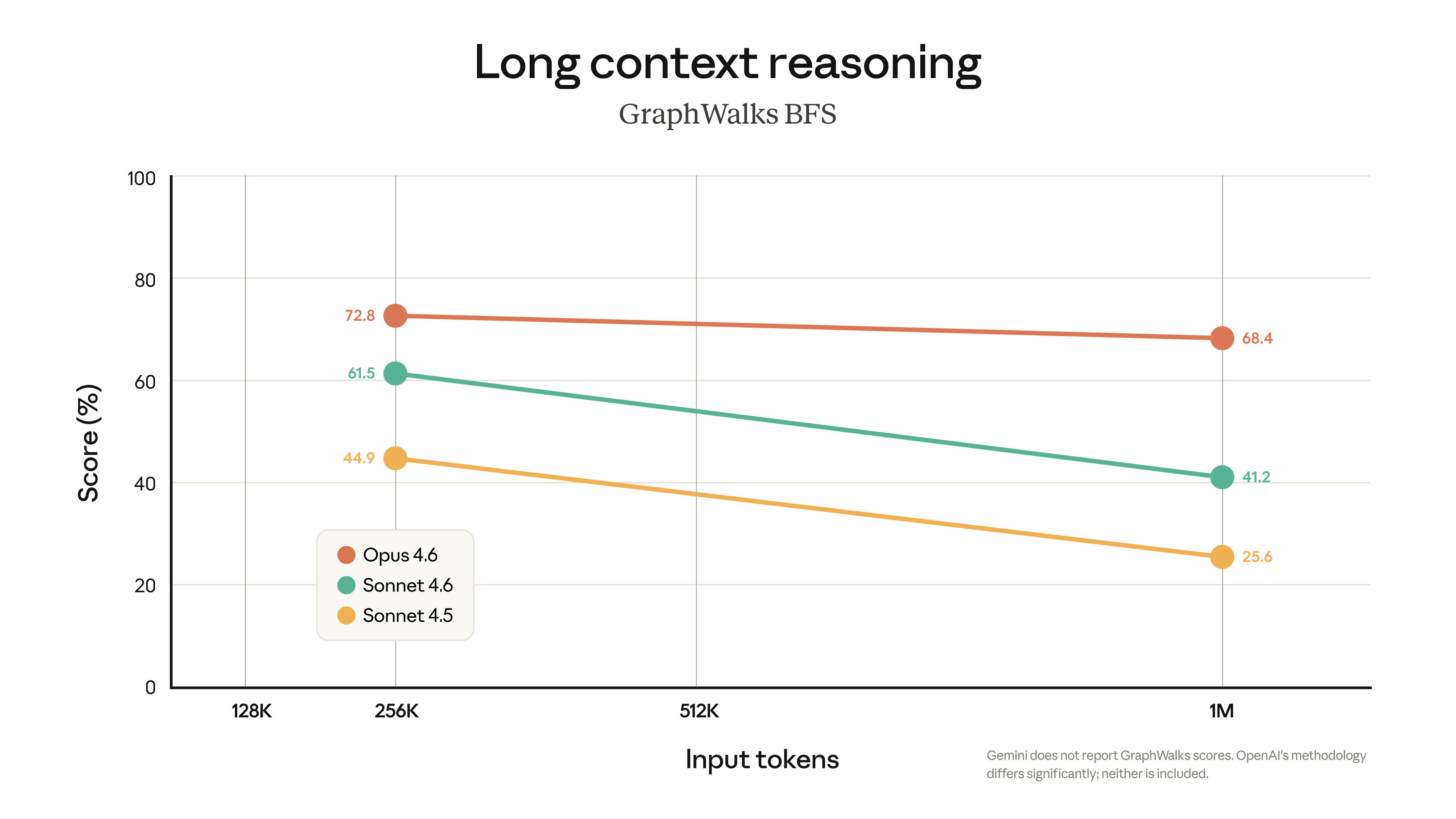
Here’s where it gets interesting. Anthropic didn’t just announce 1M tokens. They posted a benchmark chart showing retrieval quality at scale, and it tells a brutal story:
Claude Opus 4.6: 78.3% accuracy at 1M tokens
Gemini 3.1 Pro: 65.1%
GPT-5.4: collapses to 36.6%
Claude Sonnet 4.5: falls to 18.5%
So GPT-5.4 can technically accept 1M tokens. But it can only actually find things in that context about a third of the time.
Anthropic is making a smart argument here: “Sure, everyone has 1M now. But we’re the only ones who can use it properly.”
And that’s the new battleground. 💥
Not how many tokens you can accept, but how well you reason across them. And it’s exactly where DeepSeek V4’s Engram architecture ( I covered this in yesterday’s deep dive, also linked below because I missed a few things ) which retrieves static knowledge in constant time regardless of context length, is designed to compete.
The 360° Convergence Nobody’s Talking About
If you zoom out and the pattern is impossible to miss actually. I was actually focussed on just Deepseek yesterday so din’t really go comparing models but, now that I see, every serious AI lab is now building toward the same blueprint:
Sparse MoE » DeepSeek V4 activates ~32B of 1T parameters per token. Mistral Large 3 activates 41B of 675B. Sparse is the new default
1M+ context » Google, Anthropic, DeepSeek, Grok (2M). A year ago 200K was premium. Now 1M is table stakes
Native multimodal » text, image, video, code in one model. DeepSeek V4, Gemini, Grok 4, Llama 4, Qwen 3.5 — all native
Aggressive pricing » DeepSeek at $0.30/1M. Gemini Flash at $0.30/1M. GPT-5 at $1.25/1M, down from GPT-4’s $30/1M. That’s roughly a 100x collapse in two years
Open weights » DeepSeek (expected MIT/Apache), Mistral (Apache 2.0), Llama, Qwen, GLM-5. Open-weight models now trail proprietary ones by about three months
👉 No single lab leads on all five.
DeepSeek V4 is trying to be the first to hit all five at once. That’s what makes it matter, not that it’s better on any one axis, but that it’s forcing a convergence that reshapes the entire market.
And the convergence itself is the real story. Not DeepSeek vs Anthropic. Not China vs the West. But the fact that the model is becoming infrastructure, like cloud compute, earlier and like bandwidth, where the long-term trend is relentlessly cheaper, more capable, and more interchangeable.
If you’re building products on top of AI, your costs are collapsing, your context windows are exploding, and your switching costs are dropping. so the point remains the same that I made yesterday in fact this Anthropic announcement just proved the theory. and,
This is the best news the application layer has had in years. 🥳
What I published Yesterday!
A deep dive on DeepSeek V4 for The Intelligent Founder,
technical breakdown on Engram O(1) memory,
sparse MoE, real pricing comparisons,
risk analysis, and
the complete founder playbook
I did a bit of DeepSeek vs the West too. This convergence angle, however which I can see clearly now, is something I didn’t fully connect until Anthropic’s 1M announcement landed just now and the pattern clicked into place. I think its too important to leave out, so I’m adding it here.
This is what I do across two publications: AI Unfiltered catches the moves in real time, The Intelligent Founder AI breaks down what to actually do about them. If you're only subscribed to one, you're getting half the picture. so do sign up for both.
Follow AIU & IF.ai here -