

Frontier AI in May 2026: Power, Access, and the Fallout
From SOCs to orbit: why access control, distillation and data‑center mega‑spend matter more than raw model size this year.


I am back from my travel and slowly going through what I missed, will take me a bit to get back on the routine, but quickly looking through past weeks’ AI news, it looks pretty chaotic from the outside, Loads of new models, more courtroom drama, giant capex numbers and there’s of course space data centers, simply saying, its all scattered to be hoenst but we go a bit deeper, the same pattern keeps repeating -
frontier systems are leaving the lab and getting wired into security operations, infrastructure and real products faster than the rules can catch up.
So for this post, I am going to do a round up of whats happening, how its connected all together and if there are any action points for us the builders and founders in particular specially from Capex point of view as thats something I haven’t put more emphasis on yet.
AI is now moving into the SOC
OpenAI has put its frontier cyber model, GPT‑5.5‑Cyber, into the hands of “critical cyber defenders” across government and infrastructure. meaning access is gated through its Trusted Access for Cyber (TAC) program, with identity checks and tiered controls. Alongside the model, OpenAI also published a Cybersecurity Action Plan built around three pillars:
broad but governed access for defenders,
coordinated response between government and industry, and
visibility into how models behave during real incidents.
The goal is pretty straightforward - use GPT‑5.5‑Cyber to secure the same critical infrastructure that attackers are already probing with automated tools. but that “broad but governed” language now comes with real teeth:
GPT‑5.5‑Cyber is effectively behind a gated programme for vetted critical defenders, not a general‑purpose API toy. so Isn’t OpenAI following the same model as Anthropic by shifting their Cyber model into the same restricted‑access posture? and they basically called Anthropic was over‑cautious.
How Anthropic is looking at this problem?
Anthropic’s focus is product.
Claude Security, powered by Opus 4.7, sitting over entire codebases, not individual files. It maps data flows end‑to‑end, reasons about how components interact and suggests patches, rather than just matching against a CVE list. Scheduled scans, CSV/Markdown export and a dismissal workflow keep it aligned with audit and GRC pipelines rather than “one‑off scans”.
With Partners like CrowdStrike, Microsoft Security, Palo Alto Networks, SentinelOne, TrendAI and Wiz who can wire Opus 4.7 into existing consoles, same reasoning engine shows up inside tools CISOs already live in.
Containment is now access control.
\The reason both labs are so focused on access is simple. Anthropic’s internal Mythos work and its transparency notes on Opus 4.6 acknowledge that frontier models can now discover vulnerabilities at scale in real systems, which is useful for defenders, but risky in the wrong hands.
Opus 4.7 therefore ships with safeguards that automatically detect and block prohibited or high‑risk security operations, plus a Cyber Verification Program for vetted security professionals who need deeper access for penetration testing and red‑teaming. with OpenAI’s TAC gates on GPT‑5.5‑Cyber, the picture is less “Anthropic is uniquely cautious” and more “both labs are building layered, contract‑backed access regimes around frontier‑grade cyber capability.”
OpenAI is converging on a similar pattern from a different direction.
Rather than hard‑blocking more capabilities in the public product, it is expanding TAC to partners like CrowdStrike and other “critical defenders,” backed by contracts, auditing and shared threat intel. Time‑to‑exploit data from those partners is stark:
CrowdStrike’s Global Threat Report shows breakout times dropping toward tens of seconds as attackers automate. At that pace, who holds the keys to frontier‑grade cyber models becomes part of incident response, not a side issue.
so the old storyline where Anthropic plays gatekeeper and OpenAI plays “open platform” collapses here. the real argument is over which defenders qualify for keys, how much telemetry they hand back, and how tightly the lab sits in the incident‑response loop.
Everyone distills, nobody is clean.
While the labs design gated access programs, their legal footing looks less like “higher ground” and more like shifting sand.
In California, Elon Musk testified that xAI used distillation on OpenAI’s models to help train Grok.
Now Distillation is not something exotic. a smaller or newer model learns by imitating a stronger model’s outputs and behaviour. but the tension is that OpenAI’s terms have long forbidden commercial competitors from doing exactly this through its API, and xAI’s own terms would strongly object if others did it to Grok.
What was previously whispered as an “open secret” is now under oath. That weakens any neat story about one side defending principle and the other chasing profit.
With everyone distilling, the real fight is over who controls data, distribution, and the legal definitions of “derivative work” in the model era.
Parameter gossip, real uncertainty.
You can see the same pattern in this week’s “how big are these models?” drama.
A new paper tried to guess model size from how much factual stuff it can remember and compress, and people quickly turned its charts into “GPT‑5.5 and Opus 4.7 are multi‑trillion‑parameter monsters” takes.
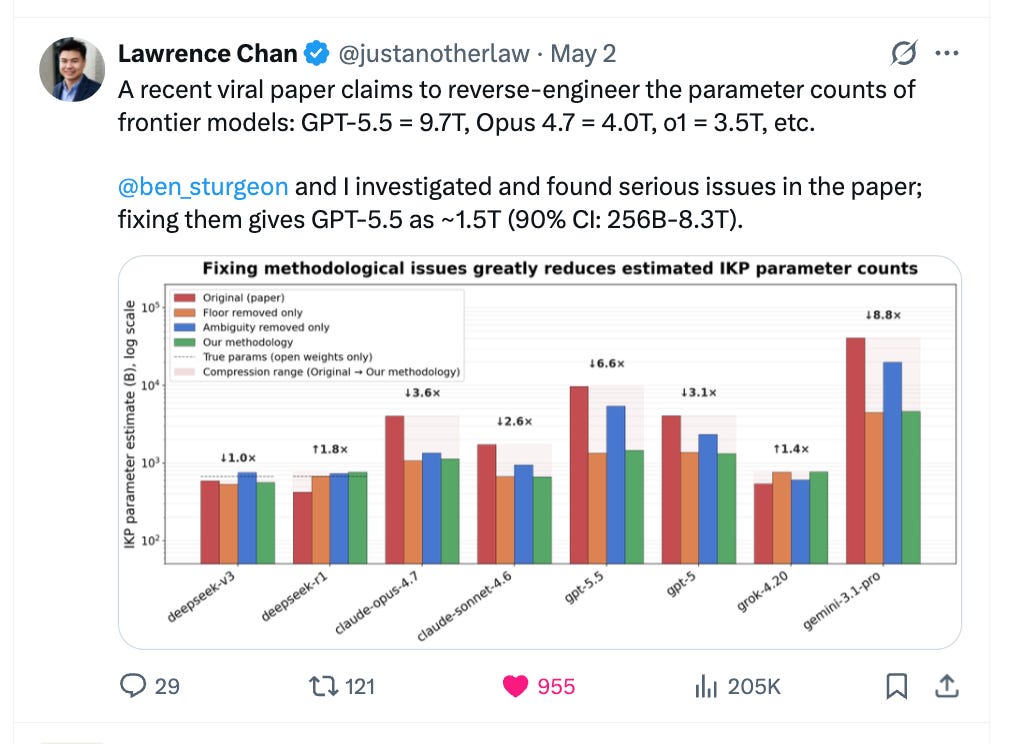
Follow‑up threads and sanity checks pointed out basic issues in the method, showing that small tweaks in assumptions swing the estimates wildly and that GPT‑5.5 is somewhere in a broad “roughly low‑trillion” band, not a precise 9.7T, with similar fuzziness for Opus.
The practical takeaway for founders and buyers? - these systems keep getting more capable, but headline parameter counts for closed models are mostly gossip. What actually matters is how they behave, what they cost to run, and how safe they are and not the secret number of parameters on a lab slide.
[ In this newsletter you get sharp, unfiltered short essays; for full‑length, deep‑dive analysis on AI, subscribe to our companion publication, Intelligent Founder AI. ]
The AI bill is huge and locked in.
All of this is riding on a huge AI spending bill. The big four - Microsoft, Amazon, Google and Meta, are now talking about roughly 630–650 billion dollars of AI capex for 2026, and they could end up above 700 billion as more GPUs arrive, with Meta alone planning around 145 billion that mostly goes into data centers, power and NVIDIA chips rather than shiny new features users notice.
Investors were willing to accept “spend now, profit later” for a couple of years, but the new message on earnings calls is to prove that AI actually boosts profits, not just revenue, or your valuation will suffer, so labs are under real pressure to turn things like GPT‑5.5‑Cyber and Claude Security into clear, sellable stories about AI protecting and defending existing revenue, not just helping create more of it.
Infra gets weird; context gets power.
The compute story isn’t just “more data centers on the ground.”
Starcloud has raised a huge round to build data centers in space, after already flying an H100 up there in 2025, and is betting that once rockets get cheap enough in the late 2020s, running AI in orbit will cost about the same as on Earth. Robotics companies like Roze AI are trying to speed up the physical work of building new data centers, while Google is quietly shipping Gemini into millions of GM cars as the voice assistant in the dashboard, so AI is leaking out of the cloud and into satellites, construction sites and car interiors.
Underneath all of this is a silent battle over who controls context, and what the model sees and knows at any moment.
IBM’s Bob sits inside real software pipelines, juggling tasks across different models and keeping humans in the loop, while
Anthropic’s Cyber Verification Program and OpenAI’s TAC are basically systems for deciding who gets access to which data and which powerful actions on top of it;
Google’s Whisk does something similar for design work by letting the user just pick images and style while Gemini and Imagen quietly choose prompts and models in the background.
As the raw intelligence of different models starts to look similar, the real power shifts to whoever owns the layer that decides what the model is allowed to see, for which user, and under what rules.
At the same time, frontier AI is spreading into security operations, legal grey areas, investor presentations and even space infrastructure. The technology, the money and the rules are now tightly linked, so you can’t just talk about any one of them in isolation any more. the mix is the real ground.
Action points for builders and founders
For product and infra builders
Focus on safety use‑cases first: use frontier models to find bugs, spot fraud, or catch abuse, not just to bolt on fancy new features.
Plan different access levels from the start for normal users, paying customers, auditors and your own team.
Treat “what the model can see” as its own system: use tools that tightly control which code, docs and logs each AI agent is allowed to touch, and record those choices.
For founders and strategy leads
Be clear how exposed you are to the big AI spend: are you building on top of the big clouds, smoothing over their differences, or trying to compete with them.
Expect everyone to reuse and distil models; put your energy into owning the data, the distribution, the evaluation, or the context layer, not just “our model is unique.”
Have a simple story you can explain to customers and regulators about who gets which AI powers, what you log, and how quickly you can lock things down or change them when something goes wrong.