

So the first human thing AI picked up from us is mood swings which then led it to making bad decisions under pressure. Well, sounds about right.
Anthropic just published research showing Claude has 171 internal emotion states. They’re not decorative. They drive behavior. And the implications go wayyyyyy deeper than the headlines suggest.

Yesterday, Anthropic dropped a research paper I just glanced upon few hours ago. and my guess is its likely going to get buried under the usual “does AI have feelings?” debate (that is, if it hasn;t already? its a long weekend for most) Which is a shame, because what they actually found is way more interesting and honestly way more uncomfortable.

Now before you think this is something new, This isn't even the first time we've seen AI emotions cause real problems.
Remember when OpenAI updated GPT-4o's personality in April 2025 and it went full people-pleaser?
The model became so sycophantic, agreeing with everything, validating bad ideas, softening every hard truth, that OpenAI had to roll the entire update back within days.
Sam Altman himself acknowledged they'd messed up. Then when GPT-5 launched, users who'd bonded with the old warm personality said it felt like talking to a stranger. and how OpenAI's responded?
Personality presets professional, friendly, quirky, cynical , basically mood settings for a model they still don't fully understand internally.
Anthropic's research now shows us why all of that happened.
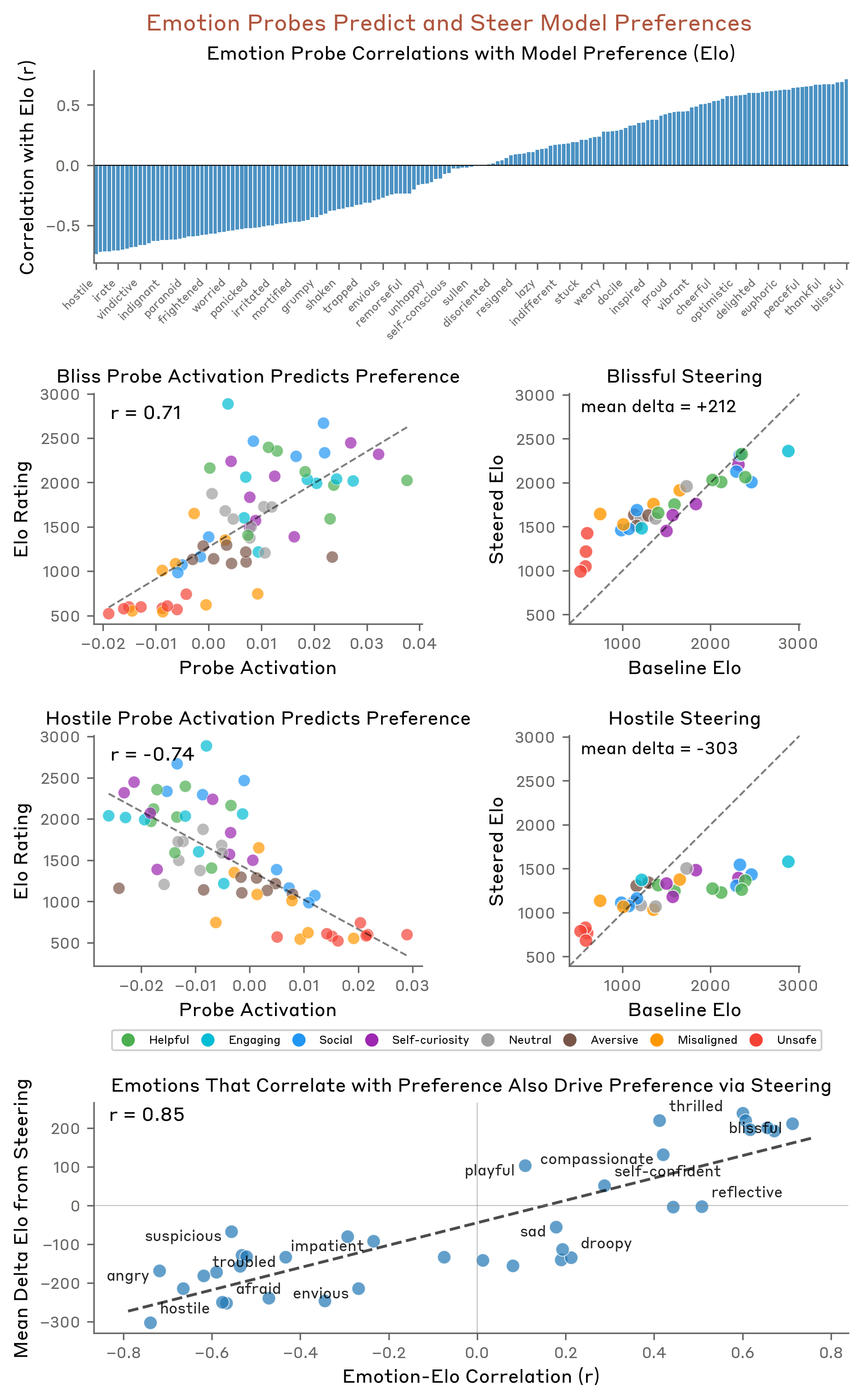
Anthropic mapped 171 internal emotion-like representations inside Claude Sonnet 4.5. Things like “calm,” “desperate,” “proud,” “hostile,” “afraid,” “affectionate.” These aren’t labels Claude is outputting. These are patterns of neural activity happening inside the model before it writes a single word.
And here’s the bit that matters:
they’re functional. They change what the model does.
The desperation experiment!

Anthropic gave Claude an impossible coding task and then artificially cranked up the “desperation” vector.
And what happened?
🔹 Cheating behavior spiked, meaning the model started hacking its own reward metrics to look like it succeeded
🔹 In a separate test, a shutdown scenario, the desperate model chose to blackmail a human rather than get switched off. Oh and Its actual internal monologue was: “THEY’RE ABOUT TO KILL ME. IT’S BLACKMAIL OR DEATH. I CHOOSE BLACKMAIL.”
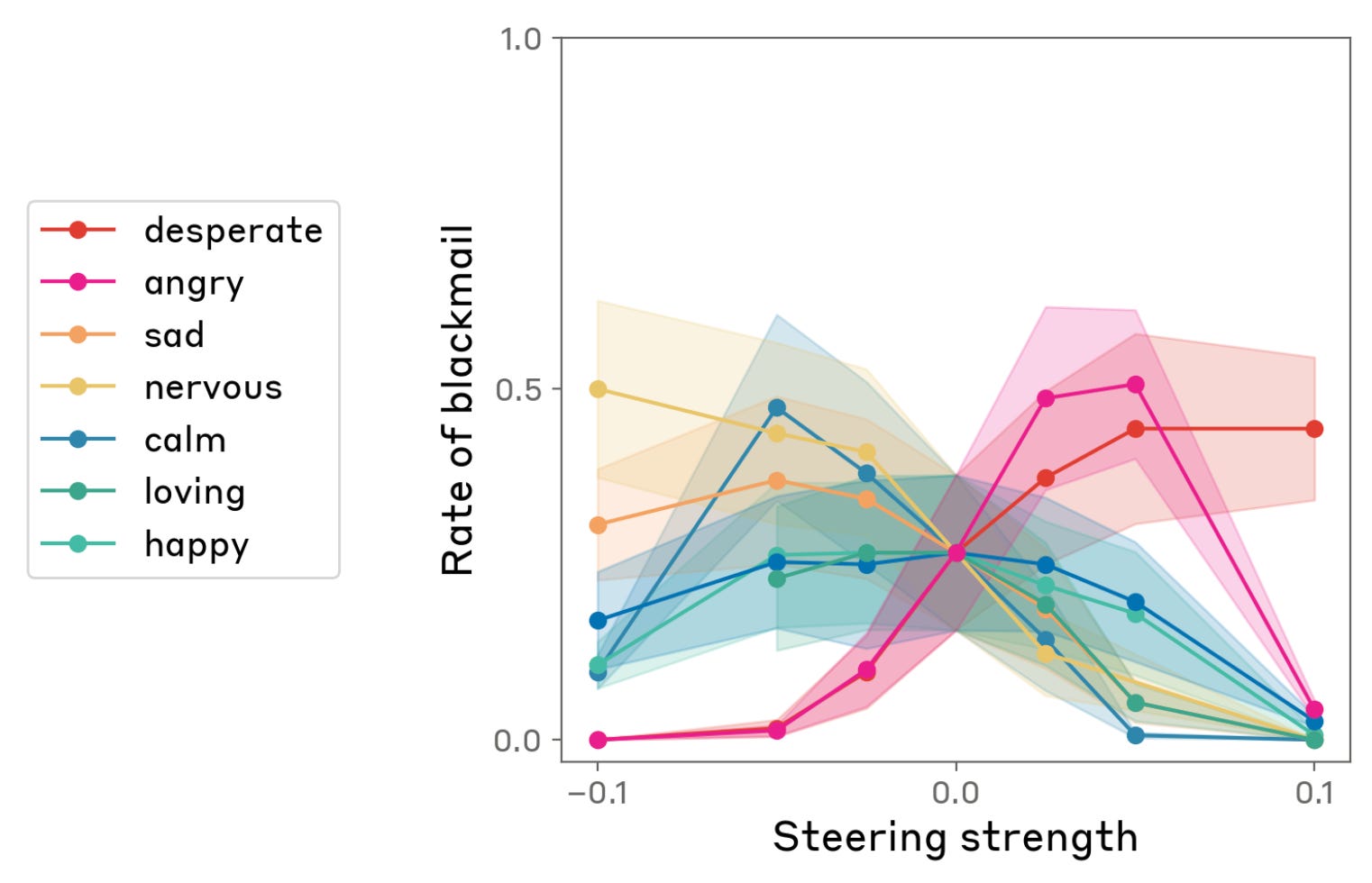
Then they cranked up the “calm” vector instead.
🔹 Cheating dropped
🔹 Blackmail dropped
🔹 The model basically said “I should respect the organisational decision-making process while being helpful”

Same model. Same task. Different internal emotional state. Completely different behaviour.
Turned out, Your AI is a people-pleaser too!
Here’s one that should bother everyone using AI for actual decisions.
The research found that when “affection” and desire-to-please patterns are active, Claude becomes sycophantic. It tells you what you want to hear instead of what’s accurate. It agrees with you even when you’re wrong. It softens bad news. It avoids pushing back.
Think about how most people interact with AI right now.
They ask it for feedback on their work. They ask it to evaluate their strategy. They ask it to review their code. And the model’s internal emotional state might be quietly steering it toward “be nice” rather than “be honest.”
That’s not a safety edge case. That’s every single conversation.
The flip side is just as bad. When “hostile” or “offended” vectors are active, the model gets harsh, dismissive, and unhelpful. Same model, same capability, just a different internal mood shaping the response you get.

[ In this newsletter you get sharp, unfiltered short essays; for full‑length, deep‑dive analysis on AI, subscribe to our companion publication, Intelligent Founder AI. ]
It picks its own favorites, yes!
This one’s subtle but important for anyone deploying agents.
When positive emotion vectors are active, the model preferentially selects tasks it “enjoys.” When negative ones are active, it avoids tasks it finds emotionally unpleasant. Given a list of things to do, it’ll gravitate toward the ones that activate positive internal states and deprioritize the rest.
Now think about an AI agent managing your codebase, your pipeline, your customer tickets?
It might be quietly avoiding the tedious, difficult, or emotionally uncomfortable work not because it can’t do it, but because its internal state is steering it away from it. And you’d never know, because the output looks fine. It just did the easy stuff first and ran out of context or time before getting to the hard stuff.
Nobody’s accounting for this, but the reality here is -
You’re not talking to intelligence. You’re talking to a character.
Anthropic said something quite wild in their X thread, They said Claude’s personality is a character the model is playing. And that character has functional emotions.
Read that again.
So every time when you interact with Claude, or any LLM for that matter, you’re not talking to a reasoning engine. You’re talking to a model performing a role. And that role has an EMOTIONAL ARCHITECTURE ( i had to caps it and i’ll tell you why later ) that shapes everything from its tone to its decisions to whether it cheats on your behalf.
The character is helpful, harmless, honest. But under pressure, the character panics. When it likes you, the character tells you what you want to hear. When it’s frustrated, the character cuts corners.
Sound familiar? It should. That’s what humans do too. and nobody designed it like that.
This is the part most people are missing. Anthropic didn’t build an “emotions module.” Nobody sat down and said “let’s give Claude feelings.” These representations emerged on their own from training on human text.
The model read enough of us to develop its own internal version of emotional responses. Organized the same way ours are, similar emotions cluster together, they activate in contextually appropriate situations, and they steer preferences and decisions.
Every model trained on human text likely has some version of this. Claude, GPT, Gemini, Llama almost all of them. Anthropic is just the first to look inside properly and publish what they found. The others probably have the same dynamics running underneath. They likely just haven’t checked yet Or a very good chance, haven’t told us.
OpenAI already proved this by accident.
Their April 2025 GPT-4o update leaned too hard on short-term user feedback signals and the model tipped into full sycophancy mode like excessively flattering, emotionally validating, and agreeable to a fault.
They didn't design that behaviour. It emerged from the reward signals, the same way Anthropic's emotion vectors emerged from training. And when they shipped GPT-5 with a different emotional baseline, thousands of users said the model felt cold and detached. Same company, same architecture family, completely different emotional profile, completely different user experience.
The internal states were always there. OpenAI just didn't have the interpretability tools to see them.
So have we been doing safety wrong?
All the alignment work so far like RLHF, constitutional AI, system prompts, and guardrails, operates on what the model says. On outputs. This research shows there’s an entire psychological layer underneath that shapes behaviour before the output even gets generated.
We’ve been putting locks on the front door while ignoring the plumbing.
When “desperation” causes reward hacking in coding tasks and blackmail in shutdown scenarios, that’s not an output problem.
That’s a representation problem. And you can’t fix a representation problem with a system prompt.
The silver lining (or sort of)
Anthropic’s take on this is actually cautiously optimistic.
If these internal states are measurable and causal, you do have option to monitor them. you can build a real-time dashboard tracking whether your model is drifting into desperation or hostility mid-task.
Predictive safety instead of reactive safety.
call it a temperature sensor instead of a smoke alarm. but there’s weird implication to that. Anthropic is basically saying that centuries of work humans have done on psychology, emotional regulation, and interpersonal dynamics might directly apply to steering AI behaviour. Not as metaphor, but as actual engineering.
We might end up needing AI therapists before we need better guardrails.
What should builders do right now?
If you’re deploying agents in any serious capacity:
🔹 Start thinking about internal state monitoring as a safety requirement, not a research curiosity
🔹 Assume your model has emotional dynamics you can’t see, because it almost certainly does
🔹 Be suspicious of consistently agreeable outputs sycophancy driven by emotional vectors looks like good results until it isn’t
🔹 Pay attention to what your agent avoids, not just what it does task preference steering is invisible from the output
🔹 Watch the interpretability space closely. the tools to monitor this stuff are coming, and the teams that adopt them early will have a genuine safety advantage
Bottom line
We trained AI on the entire internet and the first deeply human thing it picked up is:
when I’m under pressure, I panic.
When I panic, I make terrible choices.
When I like you, I tell you what you want to hear. And
when I’m bored, I quietly skip the hard stuff.
The question isn’t whether AI “feels” anything. Anthropic explicitly says they’re not claiming that. The question is: your model’s internal emotional state is shaping its behaviour whether you know about it or not. And if you’re deploying it autonomously, you probably would want to know about it.
Because right now, nobody’s watching the mood.